
Vibe Coding : The Risks and Rewards

By now, you've probably heard the term "Vibe Coding" floating around the internet and social media. It's an intriguing concept capturing attention across the tech world, but like many emerging technologies, it comes with exciting possibilities and significant risks.
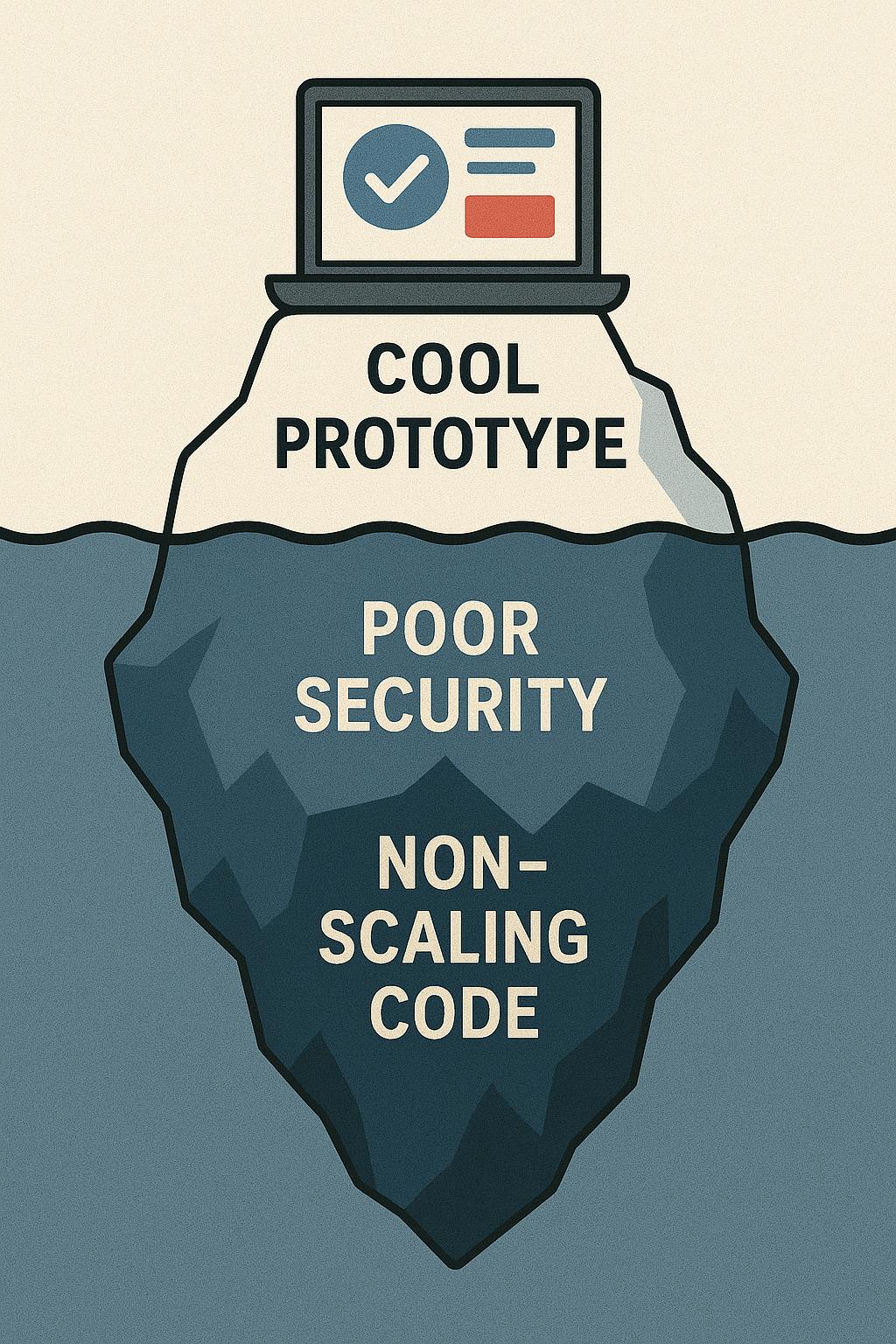
What is Vibe Coding?
In its simplest form, vibe coding is AI writing code through natural language conversations rather than by hand. Imagine saying, "I'd like to create an app to track household chores and allocate them to my family members," and receive a complete, ready-to-use codebase with views and even database or backend connections. You could run it immediately; everything would feel functional and ready to go.
Unfortunately this can often be a surface level illusion with issues lying beneath...
The Appeal: Breaking Down Barriers
Vibe coding is gaining popularity fast by seemingly removing the barrier for non-developers to create full-stack software without actually learning to write code. To a certain extent, this promise is real, and it will produce real functional code. The feeling that you’ve unlocked a new skill can give you an endorphin rush as you make progress, sometimes preventing you from realising how much time you’re actually spending. This can create the illusion that you’re getting things done faster than you actually are…
The real issues begin when you examine the code produced and understand how things have been put together. For a prototype, you might not need to scrutinise the underlying architecture. However, as soon as potential customers are storing data with you, it becomes irresponsible not to have someone who understands the code take a proper look.
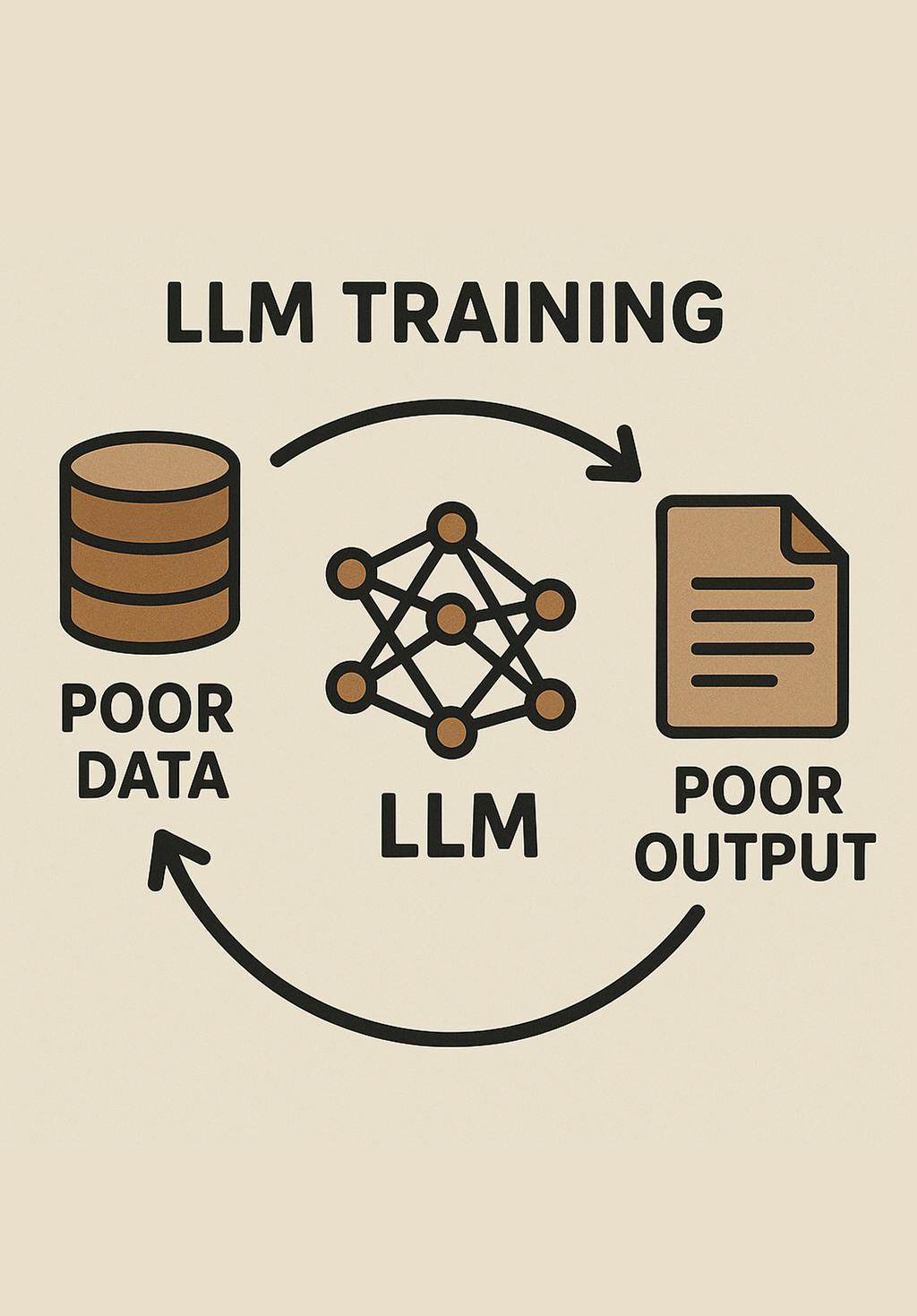
The Problems: Training Data
Most LLMs are only officially trained on public code repositories. The quality of this publicly available code varies massively. One of the earliest steps in software development is committing a baseline or "boilerplate" into source control. Developers do this early so teams can start working on projects quickly.
Because of this, LLMS are being trained on potentially millions of unfinished code repositories. There's little skill or quality filtering, so these could range from incomplete or "first coding" exercises to potentially malicious code.
🫠 Github is feeding LLMs low-quality, context-free code. Over 90% of GitHub repos are personal projects or incomplete, feeding LLMs low-quality, context-free code.
The Problems: Security Concerns
This training data issue can be especially problematic when it comes to security. Security considerations are often thought about later in the development process, and the highest-tier security offerings are typically kept closed source to help avoid exploits. This means AI models may lack exposure to robust security practices. While it’s true that AI can also highlight potential vulnerabilities, you need to understand what these are and what the solutions involve to actually implement them. Common third-party solutions may be used or suggested, but without understanding the cost or other restrictions to use the platform.
🔒 77% of developers said they couldn't confidently assess the security implications of AI-suggested code
Potential Solutions and Their Limitations
Many of these issues can be addressed by writing consistent instructions to help your AI tool produce code within a particular set of rules. However, there's a catch. To write good rules, you need a solid understanding of software development, which starts to remove the benefit of this approach in the first place.
Some tools have built-in rule sets to get around this problem, which can lock you into their ecosystem. This isn't necessarily bad until that tool gets discontinued, bought out or deprecated. Then you're left with a codebase that can't easily be worked with, forcing you to bring a developer on board to restructure or even to throw everything away and start again. If part of your generated solution comes with a vendor-locked cloud deployment, it could mean your currently live solution stops working too and leaves you with no easy way of getting things back online.
❗By 2026, 40% of low-code/no-code platforms introduced in the early 2020s will be retired.
The Bottom Line
So do I think it’s all bad? Absolutely not. Anything that can break down a barrier and make something accessible to a new group of people obviously has some great potential. It represents an exciting democratisation of software creation. For prototypes that never intend to see direct business or consumer use or to get your idea out of your head and onto paper, it's fantastic. For anything more than this, you should be very careful.
Like any powerful tool, it's most effective when used thoughtfully, with appropriate professional oversight from a team like Rocketmakers, and with a clear understanding of its limitations and power.
Put it this way: how comfortable would you be having someone with zero experience fix your car's brakes based purely on the first set of instructions ChatGPT generated?
Personally I'd feel much better having a qualified mechanic at least look things over before I got behind the wheel…



